Every year the same problem… what to buy for her birthday. While standing in line at the bakery, I started a GitHub Issue. By the time I got back to my desk, a fancy html overview was published to my GitHub Pages with a fallback to the dry markdown research. In there was the gem “Hunt A Killer: a six-month serialized murder-mystery”!

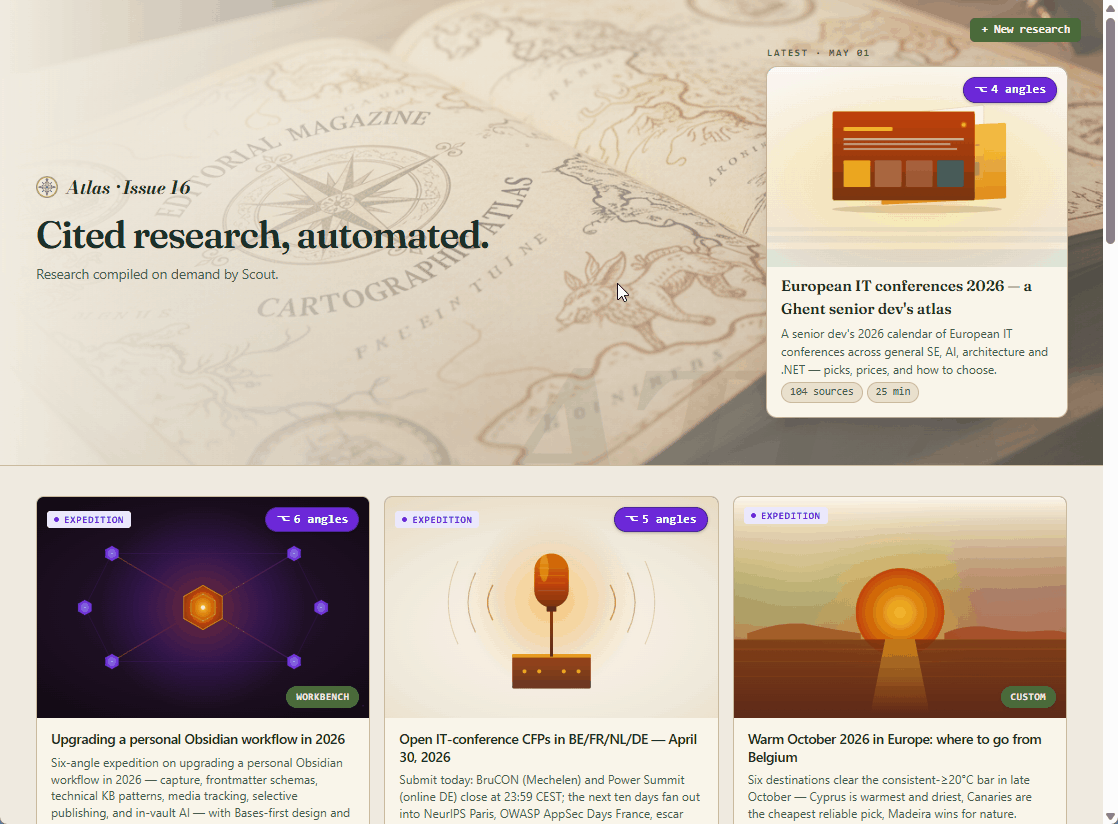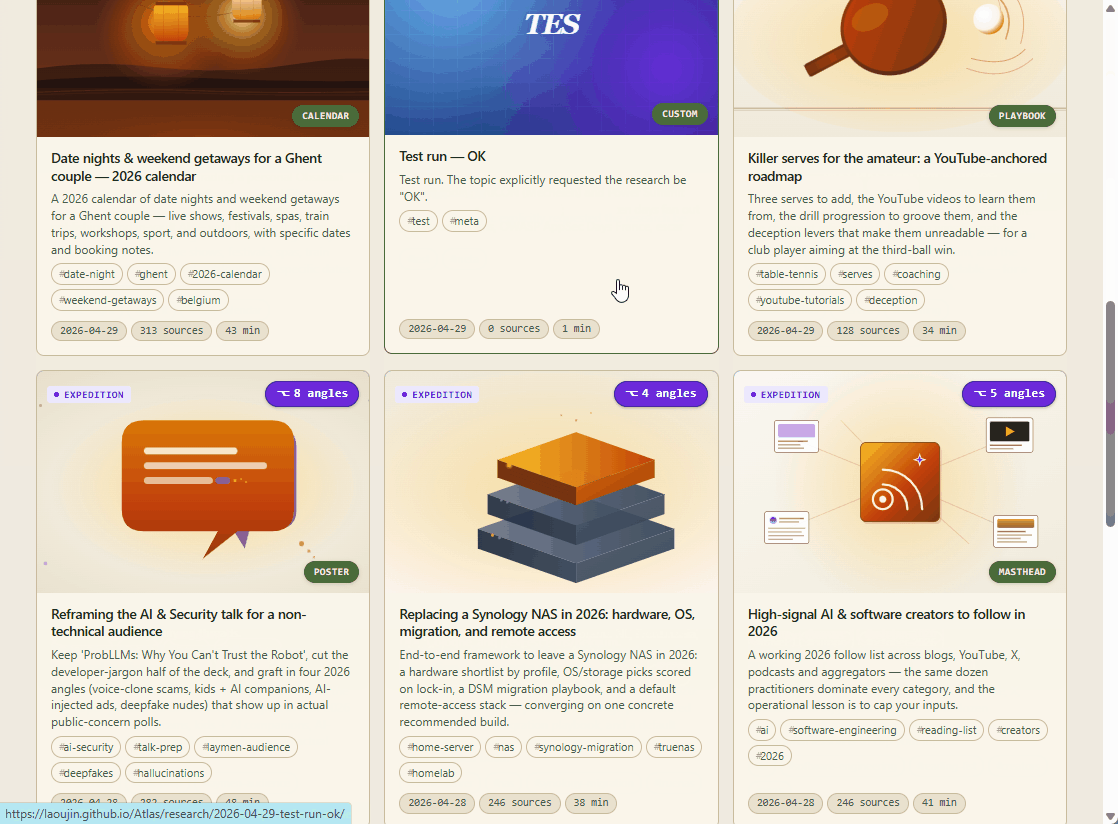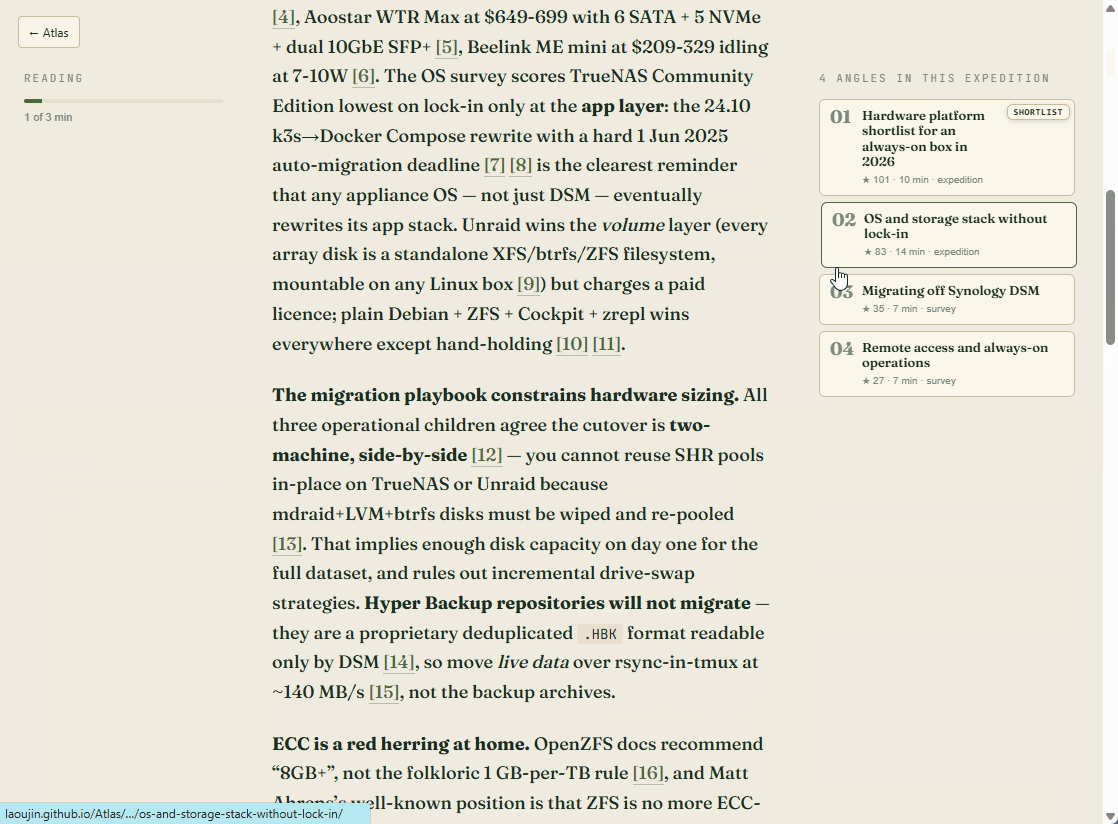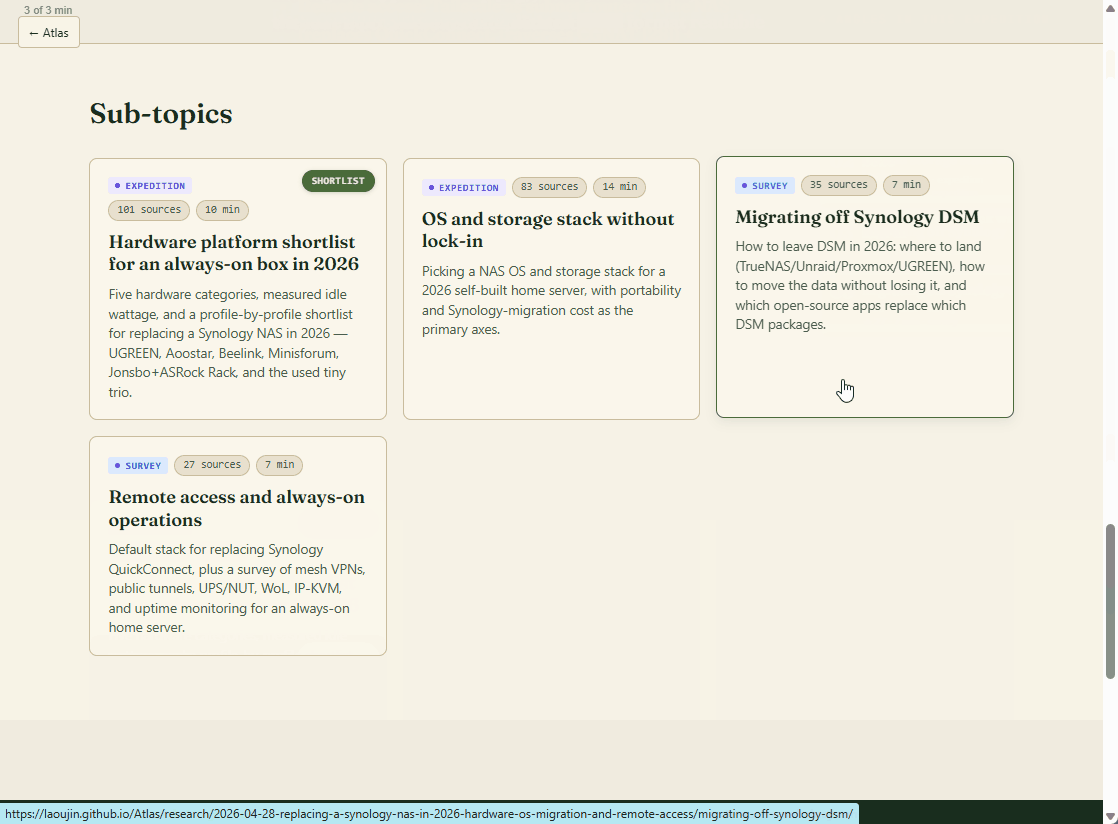
I built Scout, an MIT open-source research engine that runs Claude Code on your hardware and takes your one-line topic from a GitHub Issue to a cited markdown on a site you own. This post is about the design decisions behind it.
The pain
Most of my research curiosities show up on a phone — on a train, in line, mid-conversation. I’d start a conversation in Claude web, then by the time I’m at my desk in Claude Code I can’t find the thread — and when I do, it’s a Q&A scroll without synthesis. Useful raw, useless as context for whatever I’m building.
What I actually wanted:
- Consume later. Kick research off from anywhere; come back home (or after a night’s sleep) with the synthesis ready to drop into a Claude Code session. Bonus: by then my 5-hour Pro window has reset, so the research didn’t eat the quota I need for the actual work.
- Readable anywhere. If I’m not returning soon, I can read the published markdown on my phone — plus (optionally) a styled HTML view.
On-the-go capture, desk-side payoff.
What it is, in one diagram
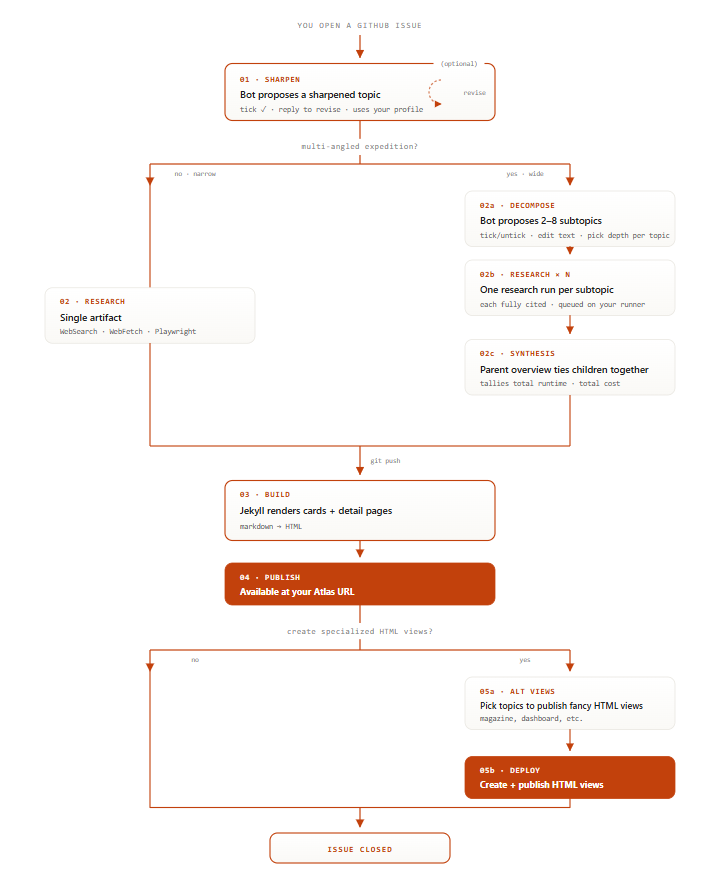
→ Open a GitHub Issue
→ Sharpen & Sub-Topics selection (optional)
→ Fancy HTML pages selection (optional)
Three Repositories
- Scout — the engine. Forked once, rarely touched.
- Atlas — your published research. All your content.
- Compass — the Jekyll theme. A submodule of Atlas.
Because Scout is your fork, I can’t do a rugpull, updates only affect me until you decide to pull in the changes.
With the Compass submodule I can add additional features like full text search, filtering, sorting etc and all you have to do is update the submodule to get these enhancements for free.
Why not just use X?
No shortage of deep-research tools out there
- gpt-researcher ⭐ 26.6k
- storm ⭐ 28.1k
- open_deep_research ⭐ 11.2k
Also Perplexity Pages, ChatGPT Deep Research, Gemini Deep Research. Scout’s pitch is narrower:
- Output you own. Markdown on a Jekyll site you host. No vendor pivot can paywall it or change the URL.
- No incremental cost. Runs against your existing Claude Pro/Max quota instead of an API bill or a second subscription.
- Forkable patterns. The sharpening prompt, decomposition strategy, and citation rule are editable text files in
skills/scout/— not a black-box service.
Other Claude Code skills exist for the raw research call (199-biotechnologies/claude-deep-research-skill, weizhena/Deep-Research-skills). Scout adds the publishing layer and the loop around the model — sharpen, decompose, cite, synthesize and add pretty views.
Decision 1: GitHub Issues as the UX
Best part of using GitHub Issues as the UX: I didn’t have to build one.
I already have the account. It’s tightly linked with the source code, ships Auth, and gives me a comment thread to converse with Claude Code plus checkboxes to kick research off.
Decision 2: Sharpen before research
The biggest single quality lever in the system isn’t the model or the search backend — it’s the sharpening step that runs before any research starts.
A user types “best NAS to buy in 2026.” That’s three different questions in a trench coat: best for what budget? Replacing what? Optimizing for storage capacity, idle wattage, or both? Without sharpening, Claude charges off in one direction and the output ignores two thirds of what the user actually meant.
So skills/scout/sharpen.md runs first: read the topic, propose a tightened framing as a comment (“Survey for replacing a Synology NAS in 2026, optimised for AVX2 + ECC, comparing UGREEN / Beelink / Minisforum and TrueNAS / Unraid / Proxmox…”), wait for tick ✓ or a steering reply. Only then does research start.
The lesson generalizes: agents that ask one clarifying question before working produce output an order of magnitude better than agents that don’t. Sharpening is cheap (one model call), and it eliminates the most common (and expensive!) failure mode — answering the wrong question.
Decision 3: Decompose wide topics into parallel sub-agent expeditions
Some questions are atomic (“best static-site generator in 2026”). Some are containers (“everything I need to leave Synology”). Trying to answer the latter in one pass produces a 4-page jumble.
For expedition depth, the sharpener also proposes 2–8 sub-topics (“hardware shortlist”, “OS/storage stack”, “DSM migration playbook”, “remote access”). Each becomes its own independent expedition, dispatched as a sub-agent in parallel. After they all finish, a synthesis pass produces a parent overview page that links each child.
This is map-reduce, but applied at the research-question level rather than the data level. Two non-obvious things matter:
- Sub-topics must be independently coherent. If sub-topic 3 needs sub-topic 1’s conclusions, you’ve decomposed wrong — collapse them.
- The synthesis pass is where most value lives. Without it, you have N disconnected pages. With it, the parent page reconciles disagreements between children and ends with a recommendation.
Decision 4: “Every claim carries its URL inline” as a skill rule
The single rule that does the most work: every factual claim, number, or quote must have its source URL next to the claim.
Why: when claims and citations are decoupled — a “References” dump at the end — the citation block is decorative. Readers can’t tell which source backs which sentence.
Forcing inline URLs ([[1]](https://...)) doesn’t stop a model from hallucinating, but it makes every claim locally auditable: one click verifies one sentence. Scout enforces this with a citations.jsonl ledger — every [[n]] marker has a matching entry pointing at a URL the model actually fetched, and a self-check reconciles the two before publish. A claim without a fetched URL fails the check.
The hallucinations that survive are the ones where the URL is real and reachable but doesn’t say what the model claims it does — smaller, and catchable in review. Cheap and effective hallucination defense.
What it costs
Measured per-run from my own Atlas (Sonnet 4.6 API):
| Tier | Mode | Time | Cost median (range) | n |
|---|---|---|---|---|
recon |
one-page | ~2 min | $0.83 ($0.73–$0.93) | 4 |
survey |
single page | 5–10 min | $2.56 ($1.99–$3.99) | 24 |
expedition |
single deep | 12–20 min | $8.64 ($7.23–$14.90) | 16 |
expedition |
multi-angle | 35–70 min | $28 ($12–$35) | 9 |
Small samples — these are my own runs, not a benchmark.
On a Pro/Max subscription, runs consume your existing quota — no API bill, but a multi-angle expedition will eat a chunk of a Pro user’s 5-hour window. Max handles them comfortably.
Try it
curl -fsSL https://raw.githubusercontent.com/Laoujin/Scout/main/install.sh
| bash -s -- --config=s5.cartography.v1
If piping curl to bash makes you twitch, read it first (~250 lines) or follow the manual install.
- Repo: github.com/Laoujin/Scout
- Live example Atlas: laoujin.github.io/Atlas
- Landing page & config picker: laoujin.github.io/Scout
What’s reusable
Sharpen first. Decompose wide topics. Inline citations as a hard rule. Use GitHub Issues so you don’t build a UI. Those four ideas port to any agent that produces long-form output — the rest of Scout is plumbing.
MIT-licensed, three-repo split (Scout / Atlas / Compass), one-line install. Fork it, take the patterns, make it your own.
⭐ github.com/Laoujin/Scout if this is useful – helps me prioritize what to build next.
PS: She’s all giddy about next month’s episode ;)
Extras
Stuff that came into being during the making of this post
-
 Laoujin/Scout: Scout: The orchestration source code
Laoujin/Scout: Scout: The orchestration source code -
 Laoujin/Atlas: Atlas: Published research
Laoujin/Atlas: Atlas: Published research -
 Laoujin/Compass: Compass: The theme layouts
Laoujin/Compass: Compass: The theme layouts